常量池其实是一个统称,具体可以分为:
- class文件常量池,参考精通JVM(一):class文件详解
- 运行时常量池
- 字符串常量池
运行时常量池
JDK1.7版本开始运行时常量池从方法区迁移到了堆中。
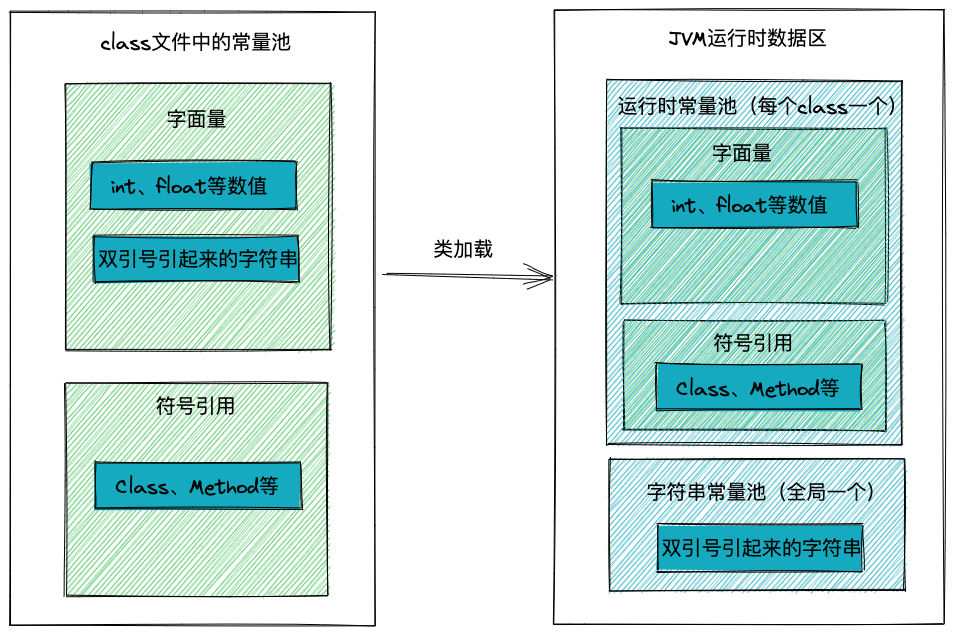
要了解运行时常量池,首先得从class文件说起。
每一个class文件中,都有一个常量池,大体分为字面量和符号引用:
- 字面量有int,float等数值型常量,还有双引号引起来的字符串值。
- 符号引用有Class、Method、Feild等。
当class文件被类加载器加载之后,运行时常量池中,每一个Class对象都有一块自己的常量池,用于存储class文件中的常量。
唯一有变化的是,JVM为双引号引起来的字符串单独开辟了一块“字符串常量池”,且这块区域是共享的,全局只有一个字符串常量池
大致示意如下:
字符串常量池的结构
JVM之所以设计一个全局的字符串常量池,是因为字符串在Java中使用的频率非常高。字符串常量池让我们能够重复利用字符串,一定程度上减少内存消耗。
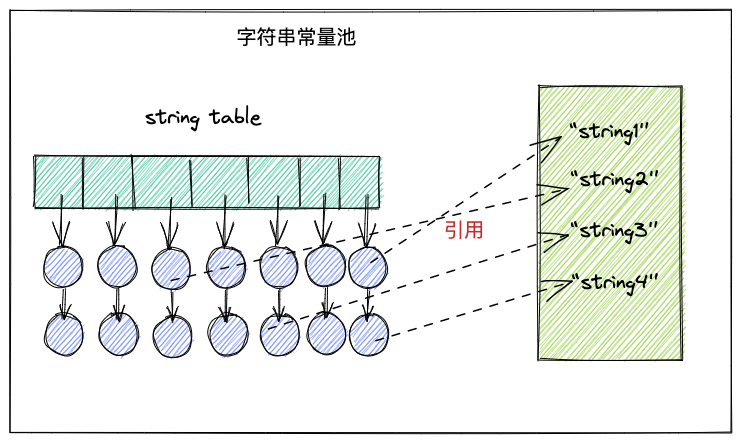
字符串常量池在JVM中的实现其实就是hashtable,是一个定长的数组。
当要把某字符串加入到字符串常量池中时,会用字符串的hashcode,对数组长度取余,得到一个数组下标。该字符串将放到这个下标的位置上。
但哈希存在碰撞的可能,也就是不同的字符串,计算得出的数组下标可能一样,因此数组中使用了一个链表来存放所有下标一样的字符串。
值得注意的是,string table中存放的是字符串的引用,而不是真实的字符串。
大致结构如下图所示:
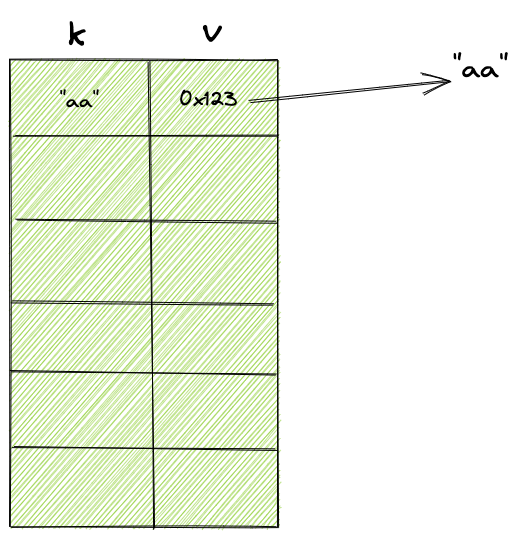
类比我们常用的hashmap,hashtable,我们可以简单的把字符串常量池理解成一个kv结构,v存的就是字符串引用。如下图:
intern()方法的作用
intern()方法是查找字符串常量池中是否由该字符串:
- 如果有,直接返回字符串的引用。
- 如果没有,把当前字符串对象放到常量池中,并返回引用
字符串对象的内存分布
String s1 = "abc";上面这行代码,当JVM执行到它时,对应的字节码指令是ldc abc,ldc指令将会去字符串常量池中找是否有abc,如果有,则直接返回。
因此内存结构是这样的:

简单改改:
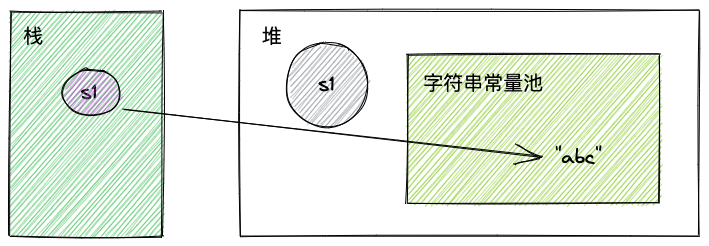
String s1 = new String("abc")此时常量池中有“abc”,堆中还会有一个String对象,且String对象的value是一个char数组,指向内存中真正的“abc”。
内存结构是这样的:
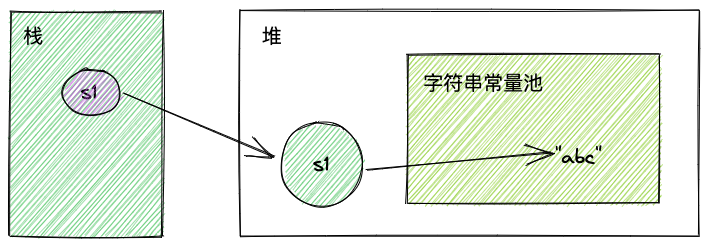
如果执行intern方法,可以得到常量池中的abc的引用
String s1 = new String("abc");
s1 = s1.intern();内存结构如下:
如果是拼接new String,拼接之后的字符串默认并不在常量池中,如:
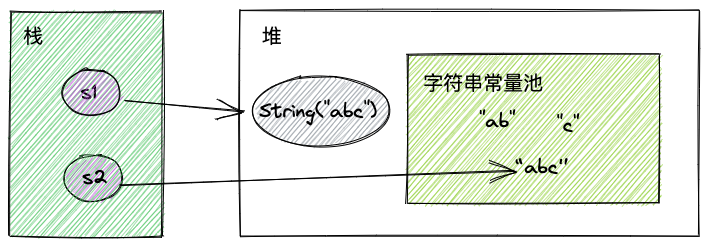
String s1 = new String("ab") + new String("c");该例子中,ab和c都在常量池中,s1对应的abc并不在常量中:
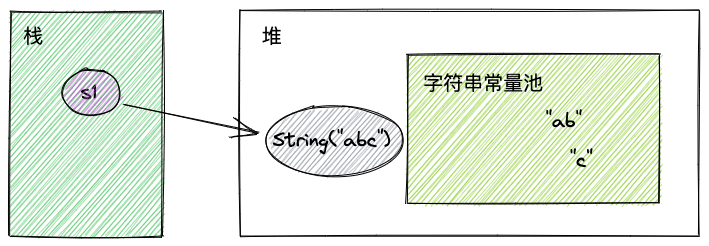
如果s1执行intern(),那么abc将进入常量池。
不过这里有一个点非常重要,字符串常量池kv结构中,v存的并不是”abc”的引用,而是String(“abc”)的引用(JDK1.7开始)。如果是JDK1.6版本,v存的仍然是“abc”的引用
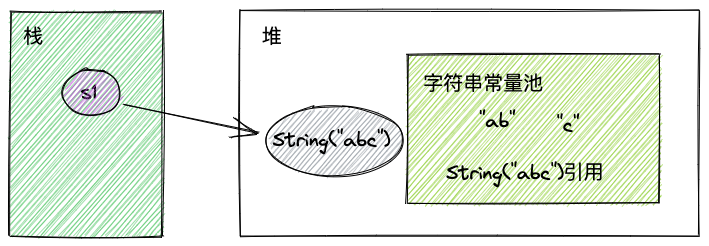
为了证明上面的观点,看下面这个例子:
String s1 = new String("ab") + new String("c");
s1.intern();
String s2 = "abc";
System.out.println(s1 == s2); // 输出true当第一行和第二行执行完之后,内存结构如上图所示。
当执行String s2 = "abc"时,ldc指令执行时去常量池中找abc,发现此时常量池中有abc,则直接返回引用。
由于kv结构中的v存的是String(“abc”)的引用,所以此时s1和s2都是指向String(“abc”)
内存结构见下图:
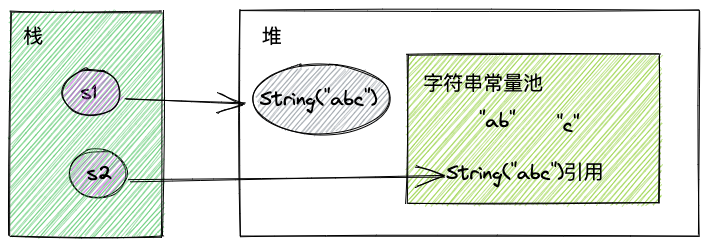
如果将intern()放到String s2 = "abc"后面:
String s1 = new String("ab") + new String("c");
String s2 = "abc";
s1.intern();
System.out.println(s1 == s2); // 输出false当第二行执行完毕之后,字符串常量池中已经有”ab”,”c”,”abc”。此时s1执行intern()没有意义,因为abc已经在常量池中。
所以此时s1指向的是字符串对象String(“abc”),而s2指向的是常量池中的“abc”,如下图: