方法执行过程
Java中方法的执行由解释器解释执行,所谓解释执行就是针对方法的字节码逐行解释,逐行执行。
解释器进行解释执行虽然比较快,但热点代码没必要每次都重复解释,因此即时编译器将热点代码编译成机器码做个缓存,速度可以大大提升。
比如有一个方法有50行字节码指令,如果是解释器,需要解释50次,因为它是逐行解释。但如果该方法多次调用后成为了热点代码,则可以将该方法编译成机器码进行缓存,那么下次执行的时候可以直接找到对应的机器码执行即可。
方法执行的全过程大致如下:
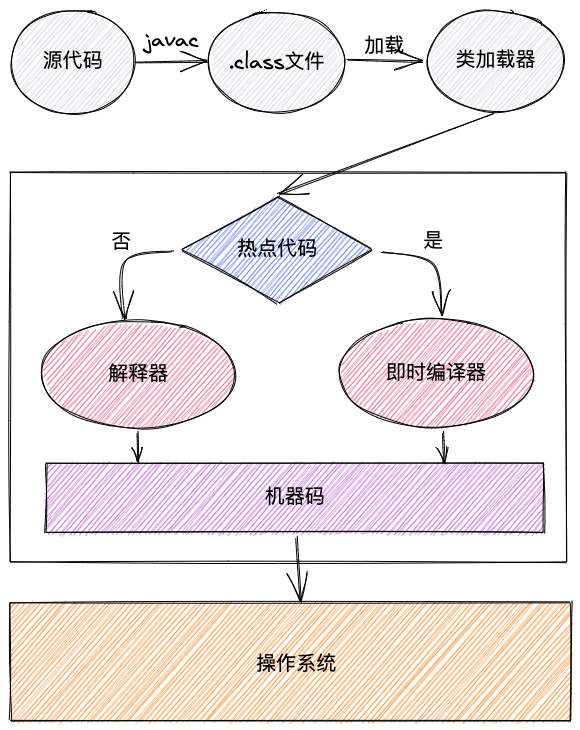
并不是所有的JVM虚拟机同时有解释器和编译器,但多数主流虚拟机都是二者共存,比如HotSpot虚拟机
热点代码
什么样的代码可以称为热点代码呢?
- 多次调用的方法
- 多次执行的循环体
无论是什么样的热点代码,编译器编译的对象都是整个方法
那么如何判断代码是否可以成为热点代码呢?
主要有两种探测方式:
- 基于采样的热点探测(经常出现在栈顶的方法即认为是热点代码)
- 基于计数器的热点探测(HotSpot虚拟机使用这种):
- 这种方法是为每个方法建立一个方法计数器,计算执行次数,达到某个阈值则认为是热点代码。
- 如果是针对循环体,则建立一个回边计数器(控制流向后跳转的指令称为回边)。
- 热点代码阈值通过
-XX:CompileThreshold设置。
值得一提的是,当方法调用次数达到阈值时,本次执行还是走解释执行,但同时会向编译器发起编译请求,下次执行该热点代码时才会用到编译后的缓存机器码
解释器
假设有这样一个方法:
public int add() {
int a = 1;
int b = 3;
int c = a + b;
return c;
}对应的字节码如下:
0 iconst_1
1 istore_1
2 iconst_3
3 istore_2
4 iload_1
5 iload_2
6 iadd
7 istore_3
8 iload_3
9 ireturn上面字节码执行过程如下:
| 指令行号 | 指令 | 作用 |
|---|---|---|
| 0 | iconst_1 | 变量1入栈 |
| 1 | istore_1 | 将栈顶元素移入本地变量表下标1位置 |
| 2 | iconst_3 | 变量3入栈 |
| 3 | istore_2 | 将栈顶元素移入本地变量表下标2位置 |
| 4 | iload_1 | 本地变量表下标1的值入操作数栈 |
| 5 | iload_2 | 本地变量表下标2的值入操作数栈 |
| 6 | iadd | 弹出操作数栈顶2个元素相加 |
| 7 | istore_3 | 将执行结果放入本地变量表下标3的位置 |
| 8 | iload_3 | 本地变量表下标3的值入操作数栈 |
| 9 | ireturn | 返回操作数栈栈顶int元素 |
上面这个字节码执行过程其实就是解释器的执行全过程
即时编译器
编译分为动态编译和静态编译,C/C++这类语言就是静态编译
即时编译器(Just In Time Compiler)也叫JIT编译器,是在运行时进行编译,也就是动态编译。它用空间换时间,加速热点代码的执行
注意:这里所说的编译是指编译成机器码,而不是Java源码编译成class文件。
JIT编译器分为了Client Complier和Server Complier两种,简称C1、C2编译器
HotSpot虚拟机会根据硬件情况自动选择哪一种方法运行,也可以使用-client、-server参数去强制指定。
为什么会有两种JIT呢?
因为这两种编译器编译的过程不同:
Client Complier专注于局部优化,拥有更快的编译速度,适合嵌入式设备等硬件条件一般的情况。Server Complier面向服务器端,拥有更高的编译质量,是一个充分优化过的高级编译器,参考JIT编译器优化

