MySQL数据
相信很多人一定很好奇MySQL中,数据到底是怎么存储的,为什么查询可以这么快?
这里我先给出一个结论:
MySQL InnoDB中,表数据是以索引的形式存储的
没错,表数据是以索引的形式存储到硬盘上的,当你新建了一张表,即使你没给这张表添加任何索引,那么这张表的数据也仍然是以索引的形式存储的
首先,我们要先了解下MySQL InnoDB中两种索引的模型
哈希索引
如果你研究过Java的hashMap,那你接下来你会感觉到无比熟悉,因为哈希索引的模型结构与Java的hashMap基本一致
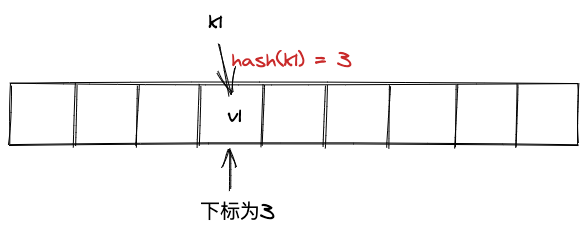
哈希索引是以K-V键值对的形式存储,将K进行哈希运算之后,得到一个哈希值,这个哈希值就是V所在的数组下标,如下图:
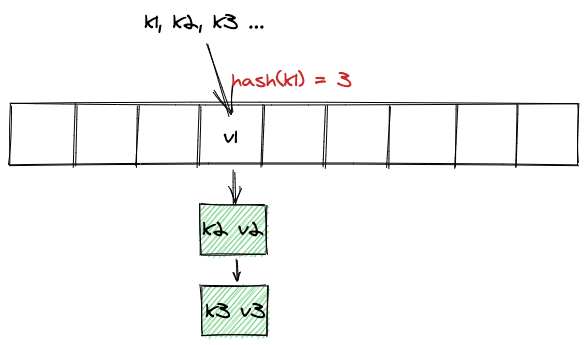
当不同的k进行哈希之后,如果刚好哈希值相同,这种情况称之为哈希碰撞,此时会以链表的形式将v串起来,如下图:
以上便是哈希索引
B+树索引
前面说过MySQL的数据本身就是以索引的形式存储的,当一张表被创建时,其实就是创建了一颗B+树。
在说B+树之前,得简单说下二叉树。
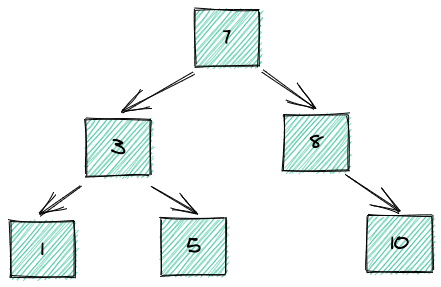
二叉树有个特点,左边节点比父节点小,右边节点比父节点大。比如有一串数据为:1,3,5,7,8,10,那么将他们挂到二叉树上将是这样:
二叉树有个缺点,当数据量大时,树的层数会非常多,检索效率很低,因此有了二叉树的进化版:多叉树。
多叉树的层级很少,检索效率高得多,而MySQL使用的是更牛逼的B+树进行索引
关于B+树,有两点值得一提:
- 最底下的节点称为叶子节点,其他节点称为非叶子节点
- 一个节点可以容纳多个数据
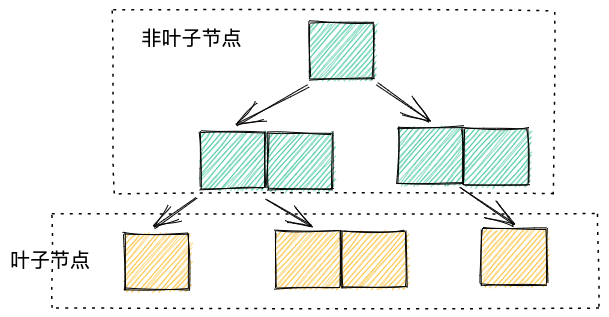
MySQL B+树索引的非叶子节点存的是主键,叶子节点存的是完整的一条记录。
主键索引
MySQL的数据本身就是一棵B+树,我们称之为主键索引
假设有一张表有3个字段,主键ID,姓名name,年龄age,有以下数据:
| 主键ID | 姓名 name | 年龄 age |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 30 |
| 3 | 王五 | 8 |
| 4 | 马六 | 43 |
| 5 | 小周 | 22 |
| 6 | 小纪 | 19 |
那么该表的数据是这样存储的:
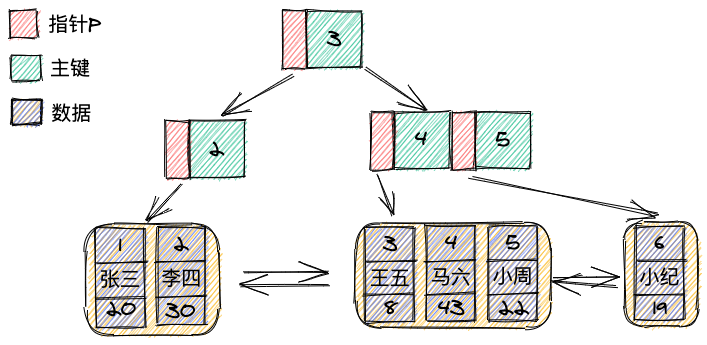
PS: 有一个在线网站可以输入数据帮你绘制B+树:B+ Tree Visualization (usfca.edu)
值得一提的是,叶子节点之间使用了双向链表连接,而且所有的数据是有序的。
当我们执行一条语句:select * from t where id between 2 and 4时,将会通过主键索引这棵B+树找到叶子节点中的(2,李四,30),然后直接通过链表指针向后遍历,直到找到(4,马六,43)结束。
非主键索引
除了主键索引,其他索引都是非主键索引。如果给刚刚的表的年龄字段增加一个索引,那么就会增加一棵B+树,并且该树的叶子节点正是表的主键,大致如下:
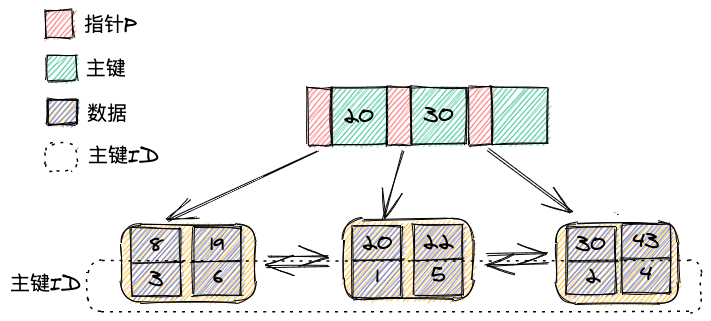
当你执行select * from age between 20 and 30时,将会使用年龄这个索引,先找到年龄为20的叶子节点,然后向后遍历,找到年龄为30的数据,最终得到三个主键值:1,5,2。示意图如下:
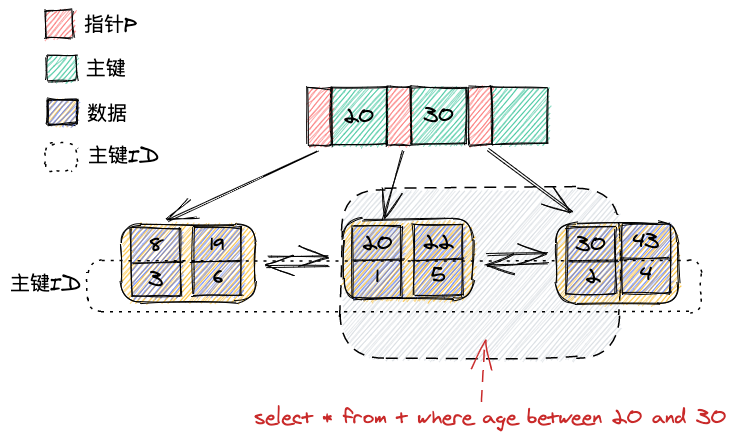
然后再用得到的主键去主键索引上查找具体的数据,这个过程有个名称,叫做回表
覆盖索引
覆盖索引并不是一种索引,而且指在某些情况下不需要进行回表。
之前提到,当执行select * from age between 20 and 30,将会先使用年龄索引找到主键,然后发生了回表,用主键去主键索引上找到具体的数据。
但如果将select * 修改为select id,在年龄索引上找到主键之后,就不需要进行回表了,因为客户端是select id,这个索引上已经有id值了,没必要再去主键索引查询。
这种情况就叫做覆盖索引,是一种常见的优化SQL语句的手段,它减少了查询次数,显著提高了性能
联合索引
联合索引就是非主键索引,只不过它进行索引的key是两个字段值,大概如下:
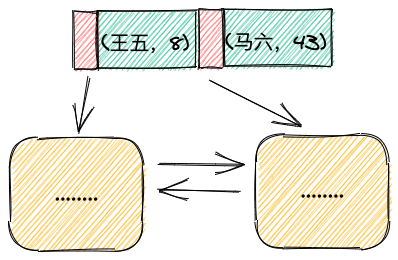
索引都是有序的,联合索引的排序如何排序呢?
假设联合索引(a, b),那么(a1, b1)和(a2, b2)进行比较大小时,是先将a1和a2比较,如果不相等,就比完了。如果相等,再用b1和b2比较。
联合索引上,也会出现覆盖索引的情况,比如(name, age)索引,当执行以下SQL时就会索引覆盖:
select age from t where name = '张三'因为在索引上通过name找到张三之后,他的age也就找到了,并不需要再去主键索引上查询

