kafka主题是以分区(Partition)的形式来存储的,什么意思呢,我们看下kafka的数据目录:

其中有一个目录是mytopic-0,这是我们之前创建的主题,这里的-0就是分区编号,目录中存放了数据文件:

我们使用--partitions 2参数创建一个2个分区的主题:
# 集群情况下,--bootstrap-server参数把所有节点地址都配进来
./kafka-topics.sh --bootstrap-server=10.211.55.3:9092,10.211.55.4:9092,10.211.55.5:9092 --create --topic test --partitions 2再看数据目录,发现了test主题有test-0和test-1两个目录:

所以所谓分区,从存储的角度来说,其实就是分成多个目录来存。
那么有什么用呢?
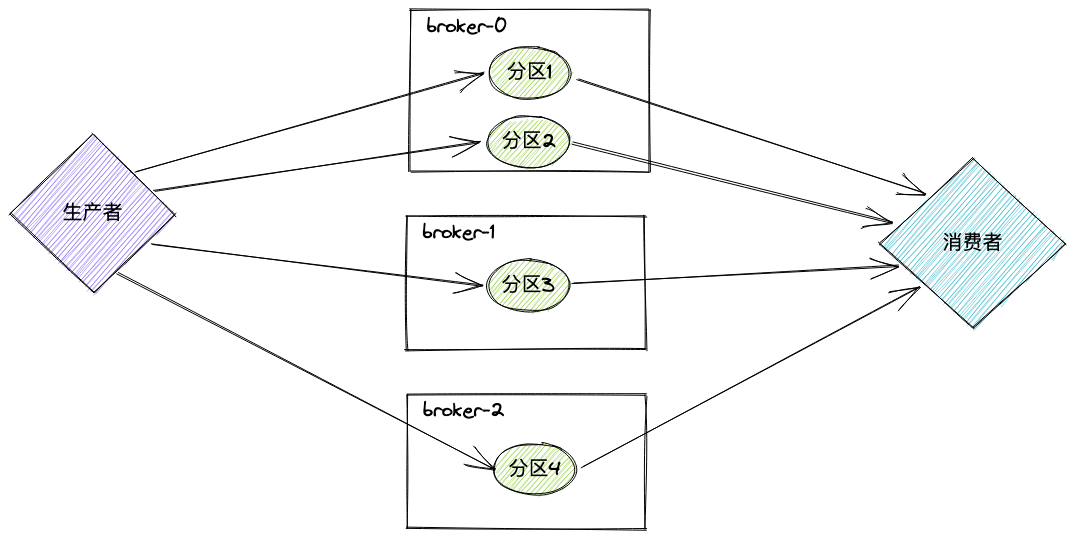
假设我们有一个3个台机器组成的kafka集群,然后创建一个4分区的主题,那么数据的存储有可能是这样的:

多节点多分区的情况下,分区是可以分布在不同节点上的,这可以带来比原来高数倍的吞吐。
因为消息的消费是按offset顺序消费的(单分区),写入和读取都要按顺序来,这意味着性能瓶颈。但有了分区之后,无论是生产者还是消费者,都可以并发的读写4个分区:
而且从数据目录中可以看到,有一个kafka自己创建的主题__consumer_offsets,足足有50个分区。
这个主题从命名上不难猜出,它是用来保存消费者offset的。当消费者消费了一条数据时,就要向broker提交offset,告诉broker我成功消费到这里了,broker就会将offset保存到__consumer_offsets主题中。
如果此时消费者重启了,就可以从__consumer_offsets中找到上次消费到哪里了,然后继续消费。
之所谓要有50个分区这么多,因为这个主题要面对所有的消费者(可能有几个甚至几十上百个消费者),分区数不足的话难以支持高并发。
当一个主题有了多个分区之后,两个消费者如果使用同样的消费组id来消费,和单分区时不一样,此时两个消费者都可以收到消息,且收到的消息是不重复的。如下图所示:

这也印证了上面说的并发读写,一个消费者来不及消费的时候,可以使用多个消费者来并发消费。
但消费者数量并不是可以无限增加的,在同一个消费组中,每一个分区,只能被一个消费者消费(为了保证分区消费顺序),也就是说,消费者数量要小等于分区数,多了也没用。
我们来总结一下消费者数量与分区数的关系:
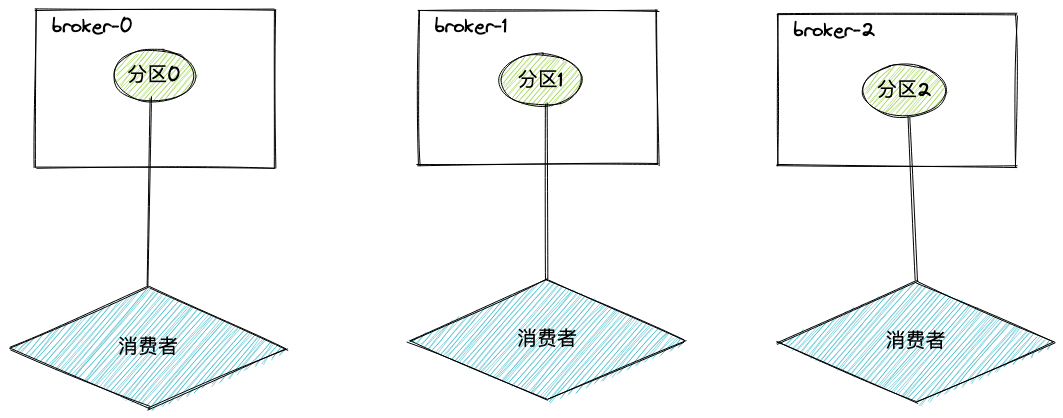
消费者数量等于分区数时,每一个消费者分别消费一个分区
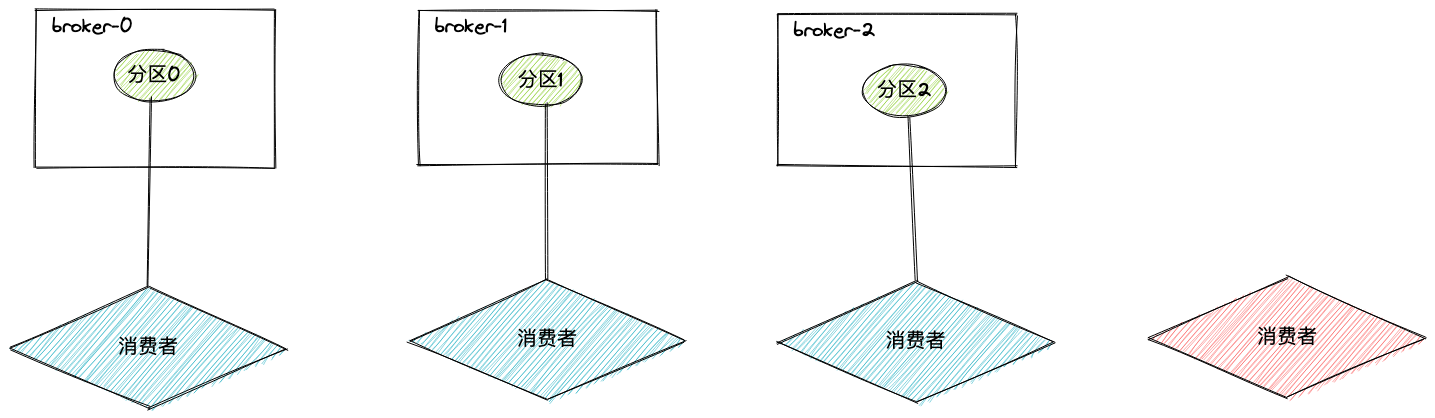
消费者数量大于分区数时,多出来的消费者消费不到数据
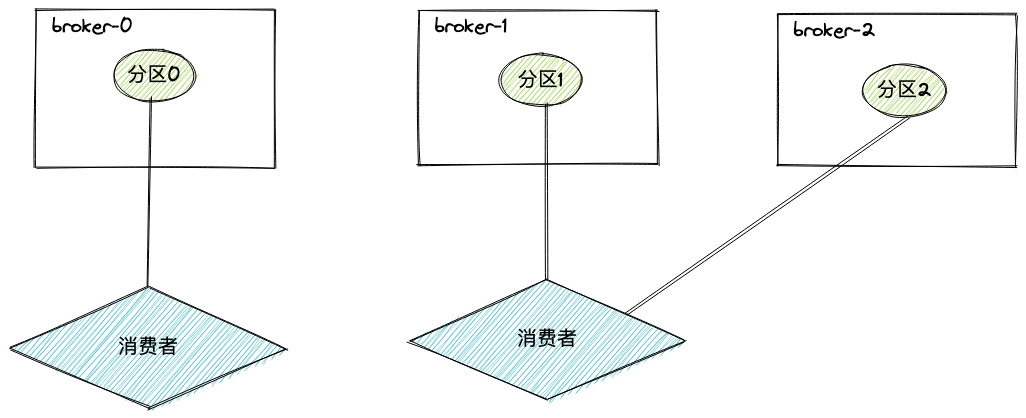
消费者数量小于分区数时,部分消费者会消费多个分区
注意:同一个分区中的消息是顺序被消费的,但不同分区之间是没有顺序关系的。

