对象创建过程
当我们执行以下代码时:
Apple apple = new Apple();大致经过三个步骤:
- 堆内存中为Apple对象开辟一块空间
- 初始化对象(成员变量赋值等)
- apple变量指向堆内存中的Apple对象的地址
其中第1、2部可以细化为:
- JVM到常量池中定位这个类的符号引用
- 确认这个类是否已加载,如未加载则进行加载
- 在堆中开辟对象内存区域
- 成员变量初始化0值
- 设置对象头中必要的信息(如GC年代信息、锁信息、对象哈希等)
- 执行
<init>方法(初始化成员变量值等)
对象的内存布局
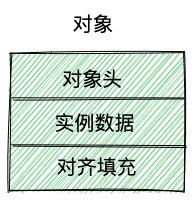
堆中的对象可以分为三个部分:
- 对象头(Header)
- 实例数据(Instance Data)
- 对齐填充(Padding)
对象头
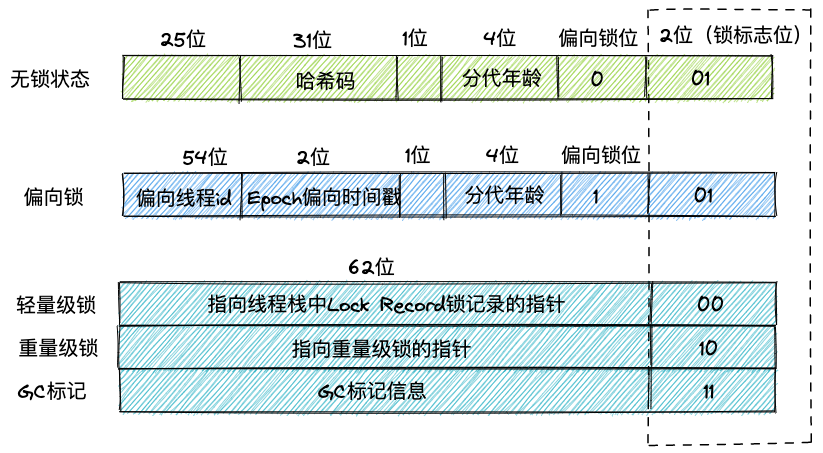
对象头中存储了两类数据:markword和类型指针。
markword,在64位系统中占用8字节空间(64bit),具体包含:哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。
但markword中所包含的数据其实加起来已经超过8字节,为了节省存储空间,在不同锁状态下,markword的结构有所不同,以此达到复用存储空间的目的。
markword示意如下:
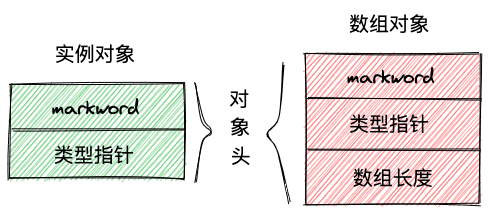
类型指针,指向方法区中该对象的class元数据。简单来说就是用来确认当前对象的class。如果开启压缩指针(JDK1.6开始默认开启),那么占用4字节,未开启则占用8字节
如果是数组对象,除了markword和类型指针之外,还有数组长度
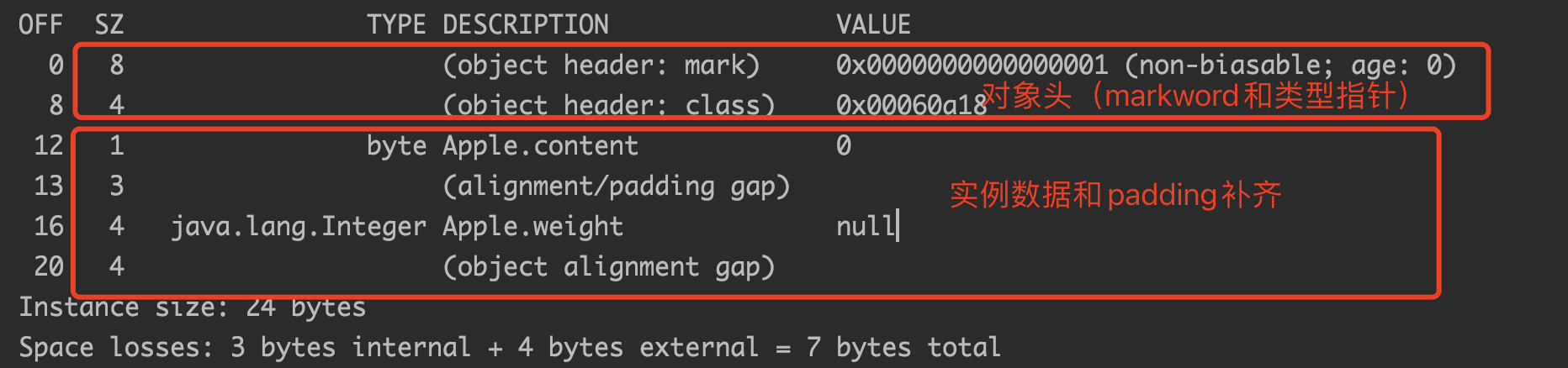
我们可以借助一个工具类打印对象头,方法如下:
Gradle:
compile group: 'org.openjdk.jol', name: 'jol-core', version: '0.16'Java:
public class Apple {
private Integer weight;
private byte content;
}
public class Test {
public static void main(String[] args) {
System.out.println(ClassLayout.parseInstance(new Apple()).toPrintable());
}
}打印结果如下:
实例数据
实例数据就是我们定义的类的成员变量数据,也就是我们开发者自定义的部分
对齐填充
JVM的内存管理要求对象起始地址必须是8字节的整数倍,所以对象头和实例数据的内存大小加起来如果不是8字节的整数倍,就用对齐填充来补全。
对象的访问定位
在运行时数据区中介绍过栈中局部变量表reference类型的数据是用于指向堆中的对象。
实际上具体的实现方式分为两种:
- 使用句柄访问
- 直接指针访问
句柄访问
使用这种方式的话,堆中将有一个句柄池,存放了对象实例所在的地址以及对象类型地址。
示意图如下:
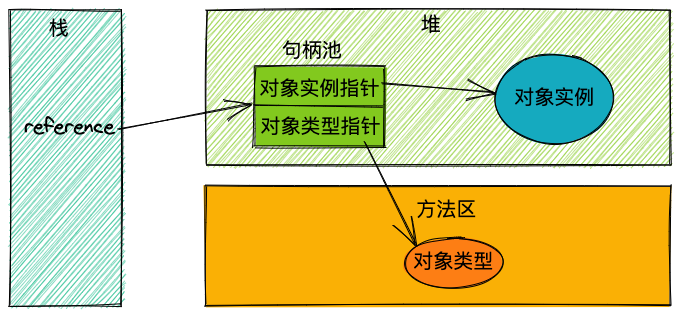
优点:reference指针是稳定地指向句柄池,如果垃圾回收器移动了对象实例,只需要改变句柄即可。
缺点:每次访问对象都需要经过句柄池,也就是需要两次地址访问才能访问到真正的对象实例
直接指针访问
这种方式就是reference直接指向了对象实例,我们常用的HotSpot虚拟机主要使用这种方式
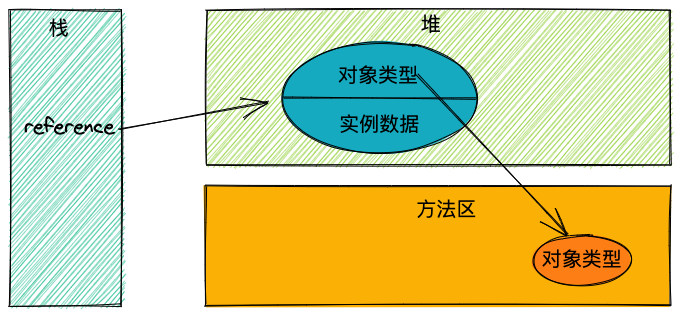
优点:比句柄方式少了一次指针定位
缺点:如果移动了实例对象,reference需要改变

